Resume Parsing: Insights and Steps to Create Your Own Parser
Resume parsing is the automated process of extracting relevant information from resumes or CVs. It analyzes the unstructured text of a resume and extracts specific details like contact information, work experience, education, skills, and achievements. The extracted data is then converted into a structured format, allowing for easy analysis and integration into recruitment systems.
Benefits of Resume Parsing
- It is a time-saving automation
- It increases efficiency in candidate screening
- Improves accuracy in data extraction
- It standardizes the data extraction and formatting
What you’ll learn from this blog:
- Resume parsing techniques for different file formats.
- Extracting specific details from resumes.
- Leveraging NLP techniques for parsing.
- Handling multicolumn resumes.
- Dockerizing the Application: Simplifying Deployment and Scalability
- Hosting it on AWS EC2.
Let’s get Started 🎉
We’ll utilize Python and its Flask framework to create a resume parsing server.
Application Flow Chart:
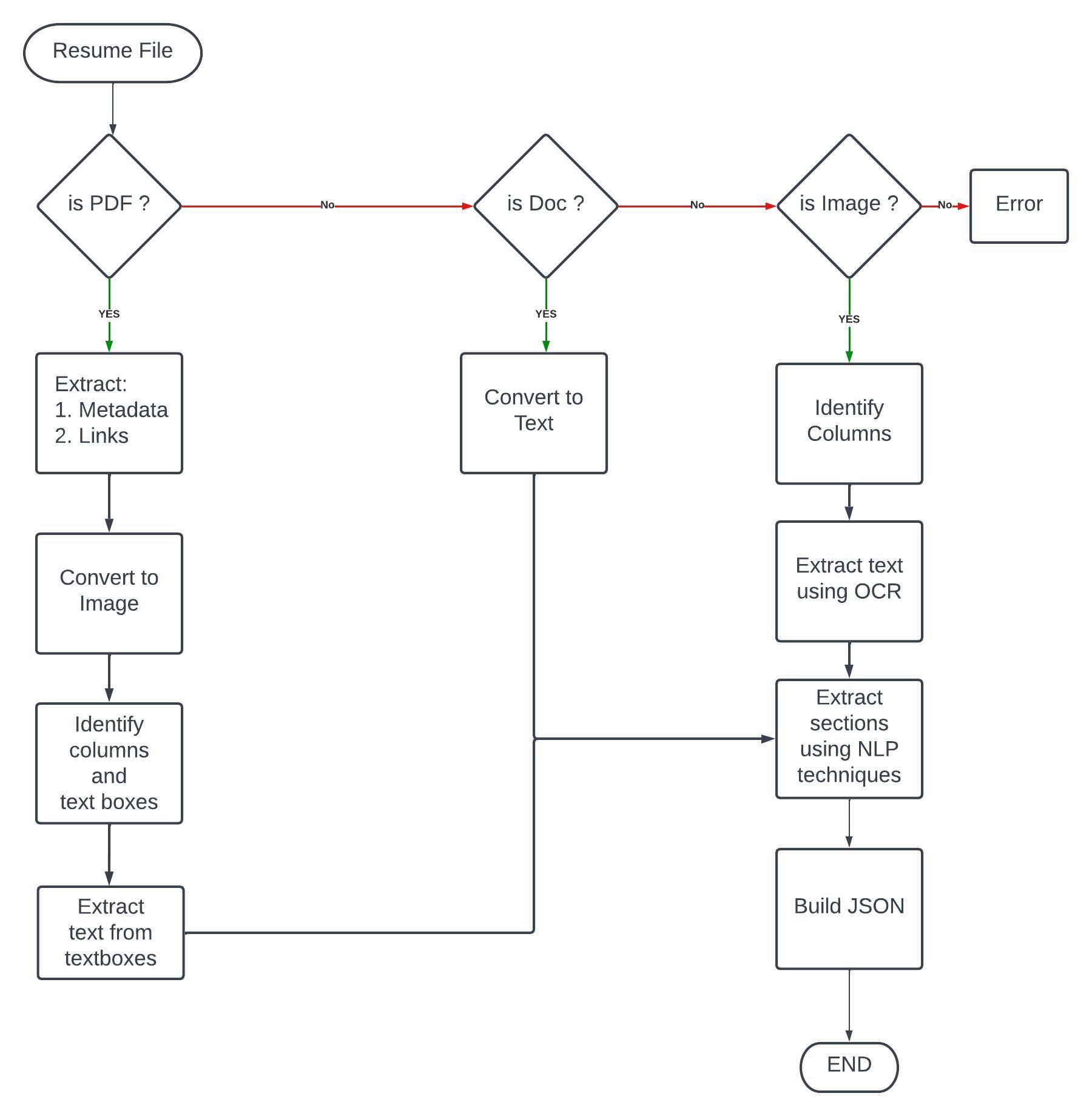
We will be primarily working on 3 categories of file formats:
- DOCX
- Images (.png, .jpg, etc.)
Data that we will be extracting
- Embedded links in PDF
- Personal data:
2.1. Name: First name and last name
2.2. Email
2.3. Phone Number
2.4. Address: City, Country, and Zip code
2.5. Links: Social and Coding Platform links - Education
3.1. Institute name
3.2. Duration: Start date and End date
3.3. Grade/CGPA
3.4. Degree - Experience
4.1. Company name
4.2. Role
4.3. Durations: Start date and End date
4.4. Skills - Certification:
5.1. Description
5.2. Duration
5.3. Skill - Project:
6.1. Project name
6.2. Skills
6.3. Description - Skills
- Achievements
- Exam scores
9.1. Exam name
9.2 Score - All other sections present in resume
Date/Duration Extraction
To extract dates from text, we will use datefinder module, and regexp to extract years.
Then we will combine these two and sort dates to get start and end date for our duration.
import re
from datetime import date
import datefinder
def get_date(input_string):
'''Get date from text'''
matches = list(datefinder.find_dates(input_string))
res = []
for i in matches:
date_str = str(i).split(' ')
extracted_date = date_str[0]
res.append(extracted_date)
return res
def get_years(txt):
'''Get years from text'''
pattern = r'[0-9]{4}'
lst = re.findall(pattern, txt)
current_date = date.today()
current_year = current_date.year
res = []
for i in lst:
year = int(i)
if 1900 <= year <= (current_year + 10):
res.append(i + "-01-01")
return res
def get_duration(input_text):
'''Get duration from text'''
dates = get_date(input_text)
years = get_years(input_text)
for i in years:
dates.append(i)
dates.sort()
duration = {
"start_date": "",
"end_date": ""
}
if len(dates) > 1:
duration["start_date"] = dates[0]
duration["end_date"] = dates[len(dates) - 1]
return duration
Extracting links from PDF:
To extract links from the PDF, we will use the python module PDFx.
import pdfx
def get_urls_from_pdf(file_path):
'''extract urls from pdf file'''
url_list = []
# for invalid file path
if os.path.exists(file_path) is False:
return url_list
pdf = pdfx.PDFx(file_path)
# get urls
pdf_url_dict = pdf.get_references_as_dict()
if "url" not in pdf_url_dict.keys():
return url_list
url_list = pdf_url_dict["url"]
return url_list
PDF to Text
import pdfx
def get_text_from_pdf(file_path):
'''extract complete text from pdf'''
# for invalid file path
if os.path.exists(file_path) is False:
return ""
pdf = pdfx.PDFx(file_path)
pdf_text = pdf.get_text()
return pdf_text
Extracting Personal Details:
We will extract text from the PDF and move ahead with further extractions.
Name
Extracting the name from the text is one of the challenging tasks.
For this, we will be using NLP: Named Entity Recognition to extract name from the text.
NLP function:
def get_name_via_nltk(input_text):
'''extract name from text via nltk functions'''
names = []
for sent in nltk.sent_tokenize(input_text):
for chunk in nltk.ne_chunk(nltk.pos_tag(nltk.word_tokenize(sent))):
if hasattr(chunk, 'label'):
name = ' '.join(c[0] for c in chunk.leaves())
names.append(name)
return names
- The text is tokenized into sentences using nltk.sent_tokenize().
- Each sentence is further tokenized into words using nltk.word_tokenize().
- The part-of-speech tags are assigned to each word using nltk.pos_tag().
- The named entities are identified by applying the named entity recognition (NER) using nltk.ne_chunk().
- For each identified named entity chunk, if it has a ‘label’, indicating it is a named entity, the individual words are concatenated to form a name.
- The extracted names are appended to the names list.
Phone Number
To extract the Phone number, we use the following module phonenumbers, we extract users country from text and using that we will extract relevant phone numbers.
import geotext
from phonenumbers import PhoneNumberMatcher
def get_phone(input_text):
'''extract phone number from text'''
phone_numbers = []
countries_dict = geotext.GeoText(input_text).country_mentions
country_code = "IN"
for i in countries_dict.items():
country_code = i[0]
break
search_result = PhoneNumberMatcher(input_text, country_code)
phone_number_list = []
for i in search_result:
i = str(i).split(' ')
match = i[2:]
phone_number = ''.join(match)
phone_number_list.append(phone_number)
for i in phone_number_list:
if i not in phone_numbers:
phone_numbers.append(i)
return phone_numbers
To extract the Email, we use the following regexp: [^\s]+@[^\s]+[.][^\s]+
def get_email(input_text):
'''extract email from text'''
email_pattern = '[^\s]+@[^\s]+[.][^\s]+'
emails = []
emails = re.findall(email_pattern, input_text)
# pick only unique emails
emails = set(emails)
emails = list(emails)
return emails
Address
To Extract address, we use the geotext module; we get City, Country, and Zipcode.
import geotext
def get_address(input_arr):
'''get address information from input array'''
input_text = " \n ".join(input_arr)
res = {}
# getting all countries
countries_dict = geotext.GeoText(input_text).country_mentions
res["country"] = []
for i in countries_dict:
res["country"].append(i)
# getting all cities
res["city"] = geotext.GeoText(input_text).cities
# zip code
pattern = "\b([1-9]{1}[0-9]{5}|[1-9]{1}[0-9]{2}\\s[0-9]{3})\b"
res["zipcode"] = re.findall(pattern, input_text)
return res
Links
As we already have a URL list from 1st operation, we will match links from a list of our own, this can be saved in any database or hard-coded, and categorize them into social or coding sections.
Other Sections
There can be many sections in a resume, that we cannot always account for. To extract them, we will create a list of possible section heading and match them against each line from the resume that we have extracted.
The code will be as following:
from utils import dynamo_db
RESUME_SECTIONS = dynamo_db.get_item_db("RESUME_SECTIONS")
def extract_resume_sections(text):
'''Extract section based on resume heading keywords'''
text_split = [i.strip() for i in text.split('\n')]
entities = {}
entities["extra"] = []
key = False
for phrase in text_split:
if len(phrase.split(' ')) > 10:
if key is not False:
entities[key].append(phrase)
else:
entities["extra"].append(phrase)
continue
if len(phrase) == 1:
p_key = phrase
else:
p_key = set(phrase.lower().split()) & set(RESUME_SECTIONS)
try:
p_key = list(p_key)[0]
except IndexError:
pass
if p_key in RESUME_SECTIONS and (p_key not in entities.keys()):
entities[p_key] = []
key = p_key
elif key and phrase.strip():
entities[key].append(phrase)
else:
if len(phrase.strip()) < 1:
continue
entities["extra"].append(phrase)
return entities
Education
To extract education, we need to identify a line from our education section that represent the school/institute name, and a line that represents the degree. After which we can search for CGPA or Percentage using regexp. For name recognition, we will make use of a list of keywords that can be present in the name.
Code to get school name, similarly we can implement to get degree as well.
import re
from utils import helper, dynamo_db
SCHOOL_KEYWORDS = dynamo_db.get_item_db("SCHOOL_KEYWORDS")
def get_school_name(input_text):
'''Extract list of school names from text'''
text_split = [i.strip() for i in input_text.split('\n')]
school_names = []
for phrase in text_split:
p_key = set(phrase.lower().split(' ')) & set(SCHOOL_KEYWORDS)
if (len(p_key) == 0):
continue
school_names.append(phrase)
return school_names
Code to extract CGPA/GPA or Percentage grade
def get_percentage(txt):
'''Extract percentage from text'''
pattern = r'((\d+\.)?\d+%)'
lst = re.findall(pattern, txt)
lst = [i[0] for i in lst]
return lst
def get_gpa(txt):
'''Extract cgpa or gpa from text in format x.x/x'''
pattern = r'((\d+\.)?\d+\/\d+)'
lst = re.findall(pattern, txt)
lst = [i[0] for i in lst]
return lst
def get_grades(input_text):
'''Extract grades from text'''
input_text = input_text.lower()
# gpa
gpa = get_gpa(input_text)
if (len(gpa) != 0):
return gpa
# percentage
percentage = get_percentage(input_text)
if (len(percentage) != 0):
return percentage
return []
Skills
In order to extract skills from the text, a master list of commonly used skills can be created and stored in a database, such as AWS DynamoDB. Each skill from the list can be matched against the text to identify relevant skills. By doing so, a comprehensive master skill list can be generated, which can be utilized for more specific skill extraction in subsequent sections.
from utils import dynamo_db
skills = dynamo_db.get_item_db("ALL_SKILLS")
def get_skill_tags(input_text):
'''Extract skill tags from text'''
user_skills = []
for skill in skills:
if skill in input_text.lower():
user_skills.append(skill.upper())
return user_skills
Experience
To extract company names and roles, a similar strategy can be employed as we used for finding school names and degrees. By applying appropriate techniques, such as named entity recognition or pattern matching, we can identify company names and associated job roles from the text. Additionally, for skill extraction, we can match the text against our previously calculated list of skills to identify and extract relevant skills mentioned in the text
Achievements and Certifications
We can use the section text that we extracted previously and for each line of it, we can search for duration and skills in it.
from utils import helper, skill_tags
def get_certifications(input_array):
'''Function to extract certificate information'''
res = {
"description": input_array,
"details": []
}
try:
for cert in input_array:
elem_dict = {
"institute_name": str(cert),
"skills": skill_tags.get_skill_tags(cert),
"duration": helper.get_duration(cert)
}
res["details"].append(elem_dict)
except Exception as function_exception:
helper.logger.error(function_exception)
return res
Projects
When it comes to extracting project titles, it can be challenging due to the variations in how individuals choose to title their projects. However, we can make an assumption that project titles are often written in a larger font size compared to the rest of the text. Leveraging this assumption, we can analyze the font sizes of each line in the text and sort them in descending order. By selecting the lines with the largest font sizes from the top, we can identify potential project titles. This approach allows us to further segment the project section and extract additional details such as skills utilized and project durations.
Link: How to find the Font Size of every paragraph of PDF file using python code?
import fitz
def scrape(keyword, filePath):
results = [] # list of tuples that store the information as (text, font size, font name)
pdf = fitz.open(filePath) # filePath is a string that contains the path to the pdf
for page in pdf:
dict = page.get_text("dict")
blocks = dict["blocks"]
for block in blocks:
if "lines" in block.keys():
spans = block['lines']
for span in spans:
data = span['spans']
for lines in data:
results.append((lines['text'], lines['size'], lines['font']))
pdf.close()
return results
Using this we find our project titles:
from utils import helper, skill_tags
from difflib import SequenceMatcher
def similar(string_a, string_b):
'''Find similarity between two string'''
return SequenceMatcher(None, string_a, string_b).ratio()
def extract_project_titles(input_array, text_font_size):
ls = []
for line_tuple in text_font_size:
line = line_tuple[0]
for s in input_array:
if similar(line,s) > 0.85:
ls.append([line_tuple[1], s])
ls.sort(reverse=True)
title_font_size = ls[0][0] if(len(ls) > 0) else 0
project_title = []
for i in ls:
if i[0] == title_font_size:
project_title.append(i[1])
return project_title
def get_projects(input_array, text_font_size):
'''extract project details from text'''
res = {
"description": input_array,
"details": []
}
txt = ' \n '.join(input_array)
project_titles = helper.extract_titles_via_font_size(
input_array, text_font_size)
project_sections = helper.extract_sections(txt, project_titles)
try:
for i in project_sections.items():
key = i[0]
txt = '\n'.join(project_sections[key])
elem_dict = {
"project_name": key,
"skills": skill_tags.get_skill_tags(txt),
"duration": helper.get_duration(txt)
}
res["details"].append(elem_dict)
except Exception as function_exception:
helper.logger.error(function_exception)
return res
Handling multicolumn resumes
Up until now, we have explored techniques to handle single-column resumes successfully. However, when it comes to two-column or multicolumn resumes, a direct extraction of text may not be sufficient. If we attempt to extract text from a multicolumn PDF using the same method as before, we will encounter challenges such as, the text from different columns will merge together, as our previous approach scans the text from left to right and top to bottom, rather than column-wise.
To overcome this issue, let’s delve into how we can solve this problem and effectively handle multicolumn resumes.
Drawing textboxes
Optical Character Recognition (OCR) comes to the rescue by identifying textboxes and providing their coordinates within the document. By utilizing OCR, we can pinpoint the location of these textboxes, which serve as a starting point for further analysis.
To tackle the challenge of multicolumn resumes, a line sweep algorithm is implemented. This algorithm systematically scans along the X-axis and determines how many textboxes intersect each point. By analyzing this distribution, potential column divide lines can be inferred. These lines act as reference markers, indicating the boundaries between columns.
Once the column lines are established, the text can be extracted from the identified textboxes in a column-wise manner. Following the order of the column lines, the text can be retrieved and processed accordingly.
By leveraging OCR, the line sweep algorithm, and the concept of column lines, we can effectively handle multicolumn resumes and extract the necessary information in an organized and structured manner.
Code:
import cv2
import fitz
from fitz import Document, Page, Rect
import pytesseract
import functools
def textbox_recognition(file_path):
'''Extract text_boxes from image'''
img = cv2.imread(file_path, cv2.IMREAD_GRAYSCALE)
ret, thresh1 = cv2.threshold(
img, 0, 255, cv2.THRESH_OTSU | cv2.THRESH_BINARY_INV)
# kernel
kernel_size = 10
rect_kernel = cv2.getStructuringElement(
cv2.MORPH_RECT, (kernel_size, kernel_size))
# Applying dilation on the threshold image
dilation = cv2.dilate(thresh1, rect_kernel, iterations=1)
# Finding contours
contours, hierarchy = cv2.findContours(
dilation, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
segments = []
text_boxes = []
# Looping through the identified contours
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
segments.append([x, x+w])
text_boxes.append((x, y, w, h))
return (segments, text_boxes)
def detect_column_lines(segments):
'''Detect column lines from segments'''
mx = max(i[1] for i in segments)
line_sweep_arr = [0 for _ in range(mx+10)]
for i in segments:
line_sweep_arr[i[0] + 1] += 1
line_sweep_arr[i[1]] -= 1
for i in range(1, mx+10):
line_sweep_arr[i] += line_sweep_arr[i-1]
line_mean = sum(line_sweep_arr)/len(line_sweep_arr)
potential_points = []
for i in range(1, mx+10):
if line_sweep_arr[i] < int(line_mean/2.5):
potential_points.append(i)
line_points = []
for i in potential_points:
if len(line_points) == 0:
line_points.append(i)
continue
prev = line_points[len(line_points) - 1]
if i == prev + 1:
line_points[len(line_points) - 1] = i
else:
line_points.append(i)
return line_points
def get_text(img, box_data):
'''Extract text from given box data'''
(x, y, w, h) = box_data
cropped_image = img[y:y+h, x:x+w]
# to show image
txt = pytesseract.image_to_string(cropped_image)
return txt
def box_coverage_percentage(x, w, line):
'''Extract coverage area in percentage for box'''
covered_width = line - x
cover_percentage = covered_width / w
return cover_percentage
def clean_text(txt):
'''Clean text'''
txt = txt.strip()
txt = txt.replace("•", '')
return txt
Y_LIMIT = 10
def custom_sort(a, b):
'''custom sort logic'''
if a[1] - Y_LIMIT <= b[1] >= a[1] + Y_LIMIT:
return -1 if (a[0] <= b[0]) else 1
return -1 if (a[1] <= b[1]) else 1
def get_boxes_for_line(text_boxes, line, ordered_text_box, prev_line):
'''get boxes with line constraints'''
temp_boxes = [i for i in text_boxes]
temp_boxes.sort(key=functools.cmp_to_key(custom_sort))
res = []
# check if 90% of box is before line
for box in temp_boxes:
if box in ordered_text_box:
continue
(x, y, w, h) = box
if (x >= prev_line - Y_LIMIT and x < line and box_coverage_percentage(x, w, line) >= 0.9):
res.append(box)
res.sort(key=lambda x: x[1])
return res
def map_size(x, org, new):
'''map box co-ordinates from image to pdf'''
return (x*new)/org
def get_text_from_pdf(box, img_shape, pdf_shape, page):
'''extract text from pdf box'''
(x, y, w, h) = box
(height, width) = img_shape
(W, H) = pdf_shape
x = map_size(x, width, W)
w = map_size(w, width, W)
y = map_size(y, height, H)
h = map_size(h, height, W)
rect = Rect(x, y, x+w, y+h)
text = page.get_textbox(rect)
return text
def image_to_text(file_path, pdf_file_path=""):
'''extract text from image'''
segments, text_boxes = textbox_recognition(file_path)
column_lines = detect_column_lines(segments)
# if single column
if len(column_lines) < 3:
return ""
# align text boxes by column
# text boxes within columns
ordered_text_box = []
for i in range(len(column_lines)):
prev_line = column_lines[i-1] if ((i-1) >= 0) else 0
boxes = get_boxes_for_line(
text_boxes, column_lines[i], ordered_text_box, prev_line)
for b in boxes:
ordered_text_box.append(b)
# boxes that are not in any column
# text boxes not in any column
non_selected_boxes = []
for i in text_boxes:
if i not in ordered_text_box:
non_selected_boxes.append(i)
for i in non_selected_boxes:
y = i[1]
if y <= ordered_text_box[0][1]:
ordered_text_box.insert(0, i)
else:
ordered_text_box.append(i)
img = cv2.imread(file_path, cv2.IMREAD_GRAYSCALE)
ret, thresh = cv2.threshold(img, 225, 255, 0)
img_shape = img.shape
pdf_shape = (0, 0)
page = None
if pdf_file_path != "":
doc = fitz.open(pdf_file_path)
page = doc[0]
pdf_shape = (page.rect.width, page.rect.height)
resume_text = ""
for i in ordered_text_box:
if pdf_file_path != "":
txt = clean_text(get_text_from_pdf(i, img_shape, pdf_shape, page))
else:
txt = clean_text(get_text(thresh, i))
resume_text += txt + "\n"
# clean text
txt = resume_text.split("\n")
res = []
for line in txt:
if len(line) == 0:
continue
res.append(line)
resume_text = ' \n '.join(res)
return resume_text
Dockerizing the Application
To make deploying the application easy we will be Dockerizing the Application.
Dockerfile
# syntax=docker/dockerfile:1
FROM python:3.9-buster
WORKDIR /resume-parser-docker
RUN mkdir input_files
RUN pip3 install --upgrade pip
COPY requirements.txt requirements.txt
RUN pip3 install -r requirements.txt
# download nltk required
RUN python -m nltk.downloader punkt
RUN python -m nltk.downloader averaged_perceptron_tagger
RUN python -m nltk.downloader maxent_ne_chunker
RUN python -m nltk.downloader words
RUN apt-get update \
&& apt-get -y install tesseract-ocr
RUN apt-get update && apt-get install ffmpeg libsm6 libxext6 -y
COPY . .
EXPOSE 5000/tcp
CMD [ "python3", "-u" , "main.py"]
Then run following commands to create image and run it.
- Build Image
docker build --tag jhamadhav/resume-parser-docker . - Run Image at port 5000
docker run -d -p 5000:5000 jhamadhav/resume-parser-docker - Check images
docker ps - Stop once done
docker stop jhamadhav/resume-parser-docker
Hosting on AWS
Now that we have a docker image of our application.
We can publish it to dockerHub:
docker push jhamadhav/resume-parser-docker
Then login to your EC2 instance and pull the image:
docker pull jhamadhav/resume-parser-docker
Run the image:
docker run -d -p 5000:5000 jhamadhav/resume-parser-docker
🎉🎉🎉 We have a fully functional Resume parser ready.
Future Work
We can make use of Large Language Models (LLM), train on datasets and fine tune LLM model to make extraction of below fields more accurate:
- School/Institute name
- Degree
- Company name
- Role in a job
Conclusion
- In conclusion, resume parsing using NLP techniques offers a streamlined approach to extract crucial information from resumes, enhancing the efficiency and accuracy of candidate screening.
- By leveraging OCR, named entity recognition, and line sweep algorithms, we can handle various resume formats, including multicolumn layouts.
- The power of NLP automates the parsing process, empowering recruiters to efficiently process resumes and make informed hiring decisions.
- Embracing resume parsing techniques ensures fair and objective evaluation of applicants, leading to successful recruitment outcomes.
- With this skillset, you can revolutionize resume processing and contribute to more efficient hiring practices.
If you have any questions, doubts, or just want to say hi, feel free to reach out to me at contact@jhamadhav.com ! I’m always ready to chat about this cool project and help you out. Don’t be shy, drop me a line and let’s geek out together!
